Reinventing GPU Performance with Cutting-Edge AI Observation
innovation, enhanced productivity, and a significant reduction in operational costs.
Extensive Data
Collection
selecting The Most
Valuable Data
Self-developed
Models
Auto scaling
& Scheduling
How It Works
Collecting Rich Data from Every Layers
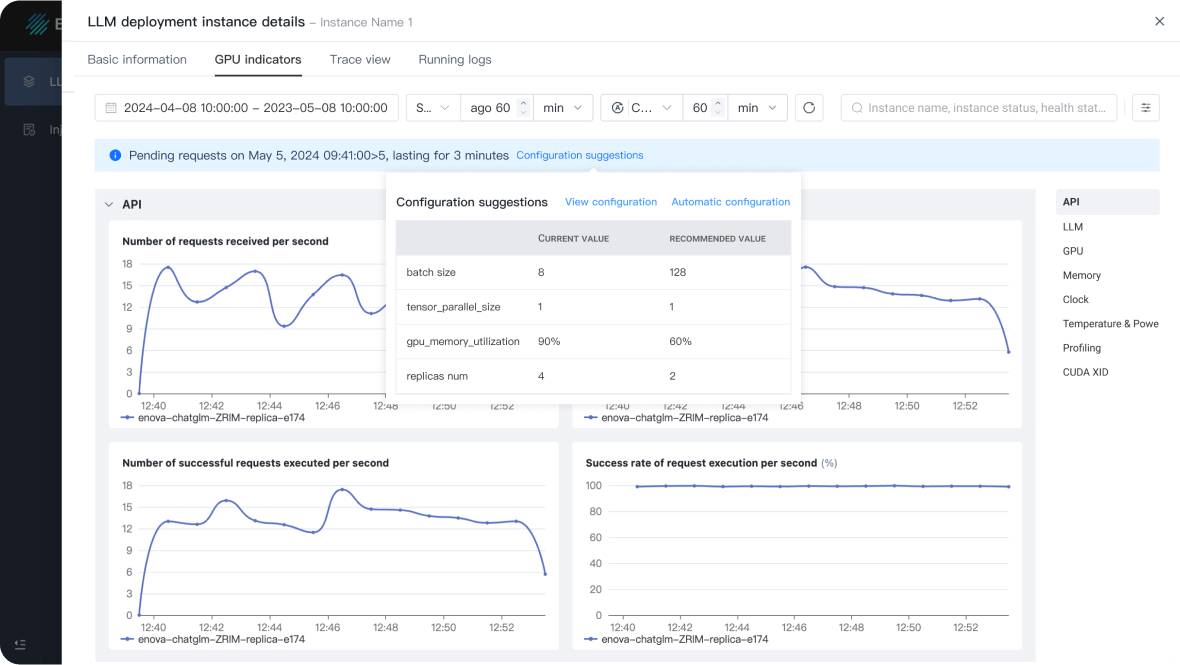
WhaleFlux collects thousands of different types of metrics from API layer, model layer and GPU layer to ensure the comprehensiveness of the observations.

Process and Analysis Metrics via Self-developed Adaptive Models
WhaleFlux has developed more than 10 adaptive models to process the massive amount of collected data. These self-developed models ensure that users get access to the most valuable metrics.

Auto-Scaling & Scheduling
By dynamically adjusting resource allocation, WhaleFlux ensures that your GPUs operate at the ideal balance of high efficiency and optimal load, thus stabilizing your systems, boosting utilization rates, and reducing unnecessary expenditures.
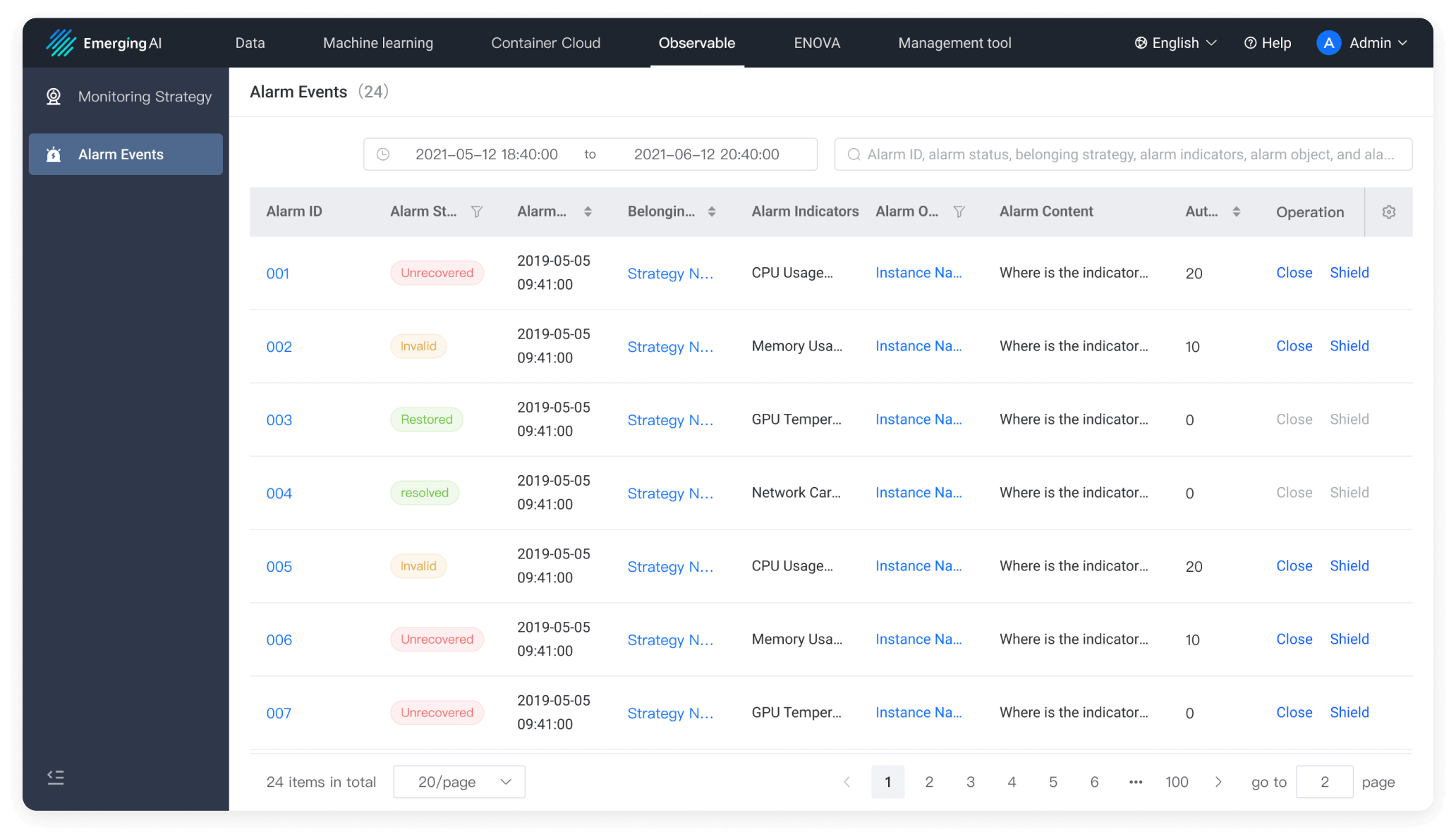
What Sets WhaleFlux Apart?
WhaleFlux selects key metrics through
Self-Developed Adaptive Models
Dynamic Auto-Scaling & Scheduling
Excellent Performance
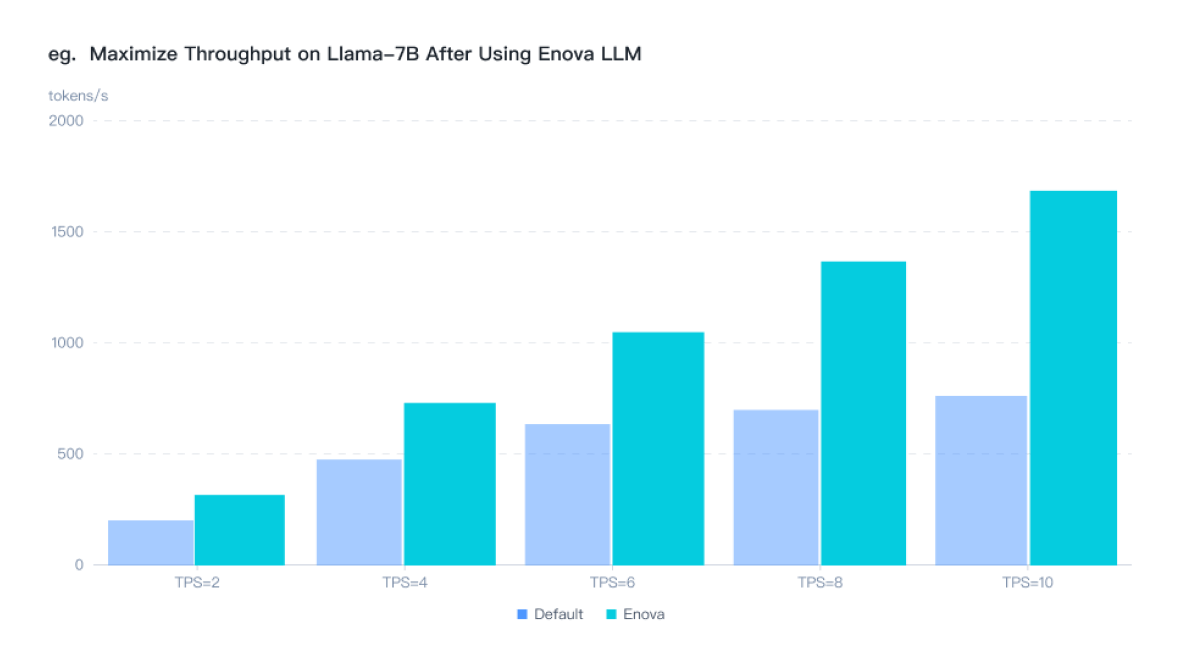
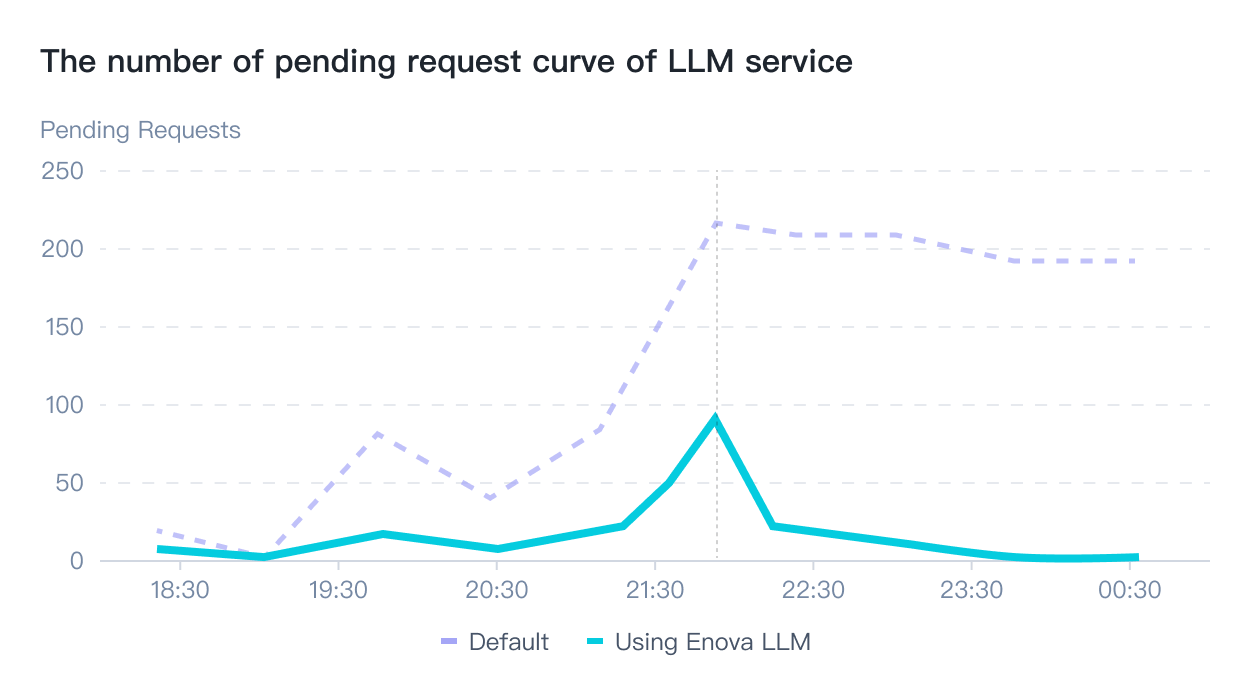
*Experiment data