Enhancing LLM Inference with GPUs: Strategies for Performance and Cost Efficiency
How to Run Large Language Models (LLMs) on GPUs
LLMs (Large Language Models) have caused revolutionary changes in the field of deep learning, especially showing great potential in NLP (Natural Language Processing) and code-based tasks. At the same time, HPC (High Performance Computing), as a key technology for solving large-scale complex computational problems, also plays an important role in many fields such as climate simulation, computational chemistry, biomedical research, and astrophysical simulation. The application of LLMs to HPC tasks such as parallel code generation has shown a promising synergistic effect between the two.
Why Use GPUs for Large Language Models?
GPUs (Graphics Processing Units) are crucial for accelerating LLMs due to their massive parallel processing capabilities. They can handle the extensive matrix operations and data flows inherent in LLM training and inference, significantly reducing computation time compared to CPUs. GPUs are designed with thousands of cores that enable them to perform numerous calculations simultaneously, which is ideal for the complex mathematical computations required by deep learning algorithms. This parallelism allows LLMs to process large volumes of data efficiently, leading to faster training and more effective performance in various NLP tasks and applications.
Key Differences Between GPUs and CPUs
GPUs and CPUs (Central Processing Units) differ primarily in their design and processing capabilities. CPUs have fewer but more powerful cores optimized for sequential tasks and handling complex instructions, typically with a few cores (dual to octa-core in consumer settings). They are suited for jobs that require single-threaded performance and can execute various operations with high control.
In contrast, GPUs are designed with thousands of smaller cores, making them excellent for parallel processing. They can perform the same operation on multiple data points at once, which is ideal for tasks like rendering images, simulating environments, and training deep learning models including LLMs. This architecture allows GPUs to process large volumes of data much faster than CPUs, giving them a significant advantage in handling parallelizable workloads.
How GPUs Power LLM Training and Inference
Leveraging Parallel Processing for LLMs
LLMs leverage GPU architecture for model computation by utilizing the massive parallel processing capabilities of GPUs. GPUs are equipped with thousands of smaller cores that can execute multiple operations simultaneously, which is ideal for the large-scale matrix multiplications and tensor operations inherent in deep learning. This parallelism allows LLMs to process vast amounts of data efficiently, accelerating both training and inference phases. Additionally, GPUs support features like half-precision computing, which can further speed up computations while maintaining accuracy, and they are optimized for memory bandwidth, reducing the time needed to transfer data between memory and processing units.
GPU-Accelerated Inference for Real-time Applications
GPUs enhance the inference of large-scale models like LLMs through strategies such as parallel processing, quantization, layer and tensor fusion, kernel tuning, precision optimization, batch processing, multi-GPU and multi-node support, FP8 support, operator fusion, and custom plugin development. Advancements like FP8 training and tensor scaling techniques further improve performance and efficiency.
These techniques, as highlighted in the comprehensive guide to TensorRT-LLM, enable GPUs to deliver dramatic improvements in inference performance, with speeds up to 8x faster than traditional CPU-based methods. This optimization is crucial for real-time applications such as chatbots, recommendation systems, and autonomous systems that require quick responses.
Key Optimization Techniques for LLMs on GPUs
Quantization and Fusion Techniques for Faster Inference
Quantization is another technique that GPUs use to speed up inference by reducing the precision of weights and activations, which can decrease the model size and improve speed. Layer and tensor fusion, where multiple operations are merged into a single operation, also contribute to faster inference by reducing the overhead of managing separate operations.
NVIDIA TensorRT-LLM and GPU Optimization
NVIDIA’s TensorRT-LLM is a tool that optimizes LLM inference by applying these and other techniques, such as kernel tuning and in-flight batching. According to NVIDIA’s tests, applications based on TensorRT can show up to 8x faster inference speeds compared to CPU-only platforms. This performance gain is crucial for real-time applications like chatbots, recommendation systems, and autonomous systems that require quick responses.
GPU Performance Benchmarks in LLM Inference
Token Processing Speed on GPUs
Benchmarks have shown that GPUs can significantly improve inference speed across various model sizes. For instance, using TensorRT-LLM, a GPT-J-6B model can process 34,955 tokens per second on an NVIDIA H100 GPU, while a Llama-3-8B model can process 16,708 tokens per second on the same platform. These performance improvements highlight the importance of GPUs in accelerating LLM inference.
Challenges in Using GPUs for LLMs
The High Cost of Power Consumption and Hardware
High power consumption, expensive pricing, and the cost of cloud GPU rentals are significant considerations for organizations utilizing GPUs for deep learning and high-performance computing tasks. GPUs, particularly those designed for high-end applications like deep learning, can consume substantial amounts of power, leading to increased operational costs. The upfront cost of purchasing GPUs is also substantial, especially for the latest models that offer the highest performance.
Cloud GPU Rental Costs
Additionally, renting GPUs in the cloud can be costly, as it often involves paying for usage by the hour, which can accumulate quickly, especially for large-scale projects or ongoing operations. However, cloud GPU rentals offer the advantage of flexibility and the ability to scale resources up or down as needed without the initial large capital outlay associated with purchasing hardware.
Cost Mitigation Strategies for GPU Usage
Balancing Costs with Performance
It’s important for organizations to weigh these costs against the benefits that GPUs provide, such as accelerated processing times and the ability to handle complex computational tasks more efficiently. Strategies for mitigating these costs include optimizing GPU utilization, considering energy-efficient GPU models, and carefully planning cloud resource usage to ensure that GPUs are fully utilized when needed and scaled back when not in use.
Challenges of Cost Control in Real-World GPU Applications
Real-world cost control challenges in the application of GPUs for deep learning and high-performance computing are multifaceted. High power consumption is a primary concern, as GPUs, especially those used for intensive tasks, can consume significant amounts of electricity. This not only leads to higher operational costs but also contributes to a larger carbon footprint, which is a growing concern for many organizations.
The initial purchase cost of GPUs is another significant factor. High-end GPUs needed for cutting-edge deep learning models are expensive, and organizations must consider the return on investment when purchasing such hardware.
Optimizing Efficiency: Key Strategies for Success
Advanced GPU Cost Optimization Techniques
Recent advancements in GPU technology for cost control in deep learning applications include vectorization for enhanced data parallelism, model pruning for reduced computational requirements, mixed precision computing for faster and more energy-efficient computations, and energy efficiency improvements that lower electricity costs. Additionally, adaptive layer normalization, specialized inference parameter servers, and GPU-driven visualization technology further optimize performance and reduce costs associated with large-scale deep learning model inference and analysis.
WhaleFlux: An Open Source in Optimizing GPU Costs
WhaleFlux is a service designed to optimize the deployment, monitoring, and autoscaling of LLMs on multi-GPU clusters. It addresses the challenges of diverse and co-located applications in multi-GPU clusters that can lead to low service quality and GPU utilization. WhaleFlux comprehensively deconstructs the execution process of LLM services and provides a configuration recommendation module for automatic deployment on any GPU cluster. It also includes a performance detection module for autoscaling, ensuring stable and cost-effective serverless LLM serving.
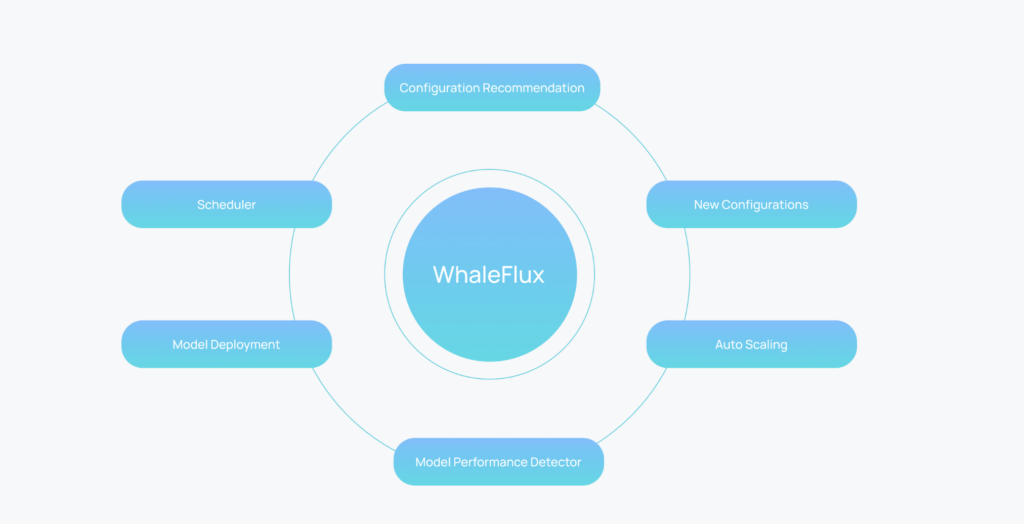
The service configuration module in Enova is designed to determine the optimal configurations for LLM services, such as the maximal number of sequences handled simultaneously and the allocated GPU memory. The performance detection module monitors service quality and resource utilization in real-time, identifying anomalies that may require autoscaling actions. Enova’s deployment execution engine manages these processes across multi-GPU clusters, aiming to reduce the workload for LLM developers and provide stable and scalable performance.
Future Innovations in GPU Efficiency
Emerging Technologies for Better GPU Performance
WhaleFlux’s approach to autoscaling and cost-effective serving is innovative as it specifically targets the needs of LLM services in multi-GPU environments. The service is designed to be adaptable to various application agents and GPU devices, ensuring optimal configurations and performance across diverse environments. The implementation code for WhaleFlux is publicly available for further research and development.
Future Outlook
Emerging technologies such as application-transparent frequency scaling, advanced scheduling algorithms, energy-efficient cluster management, deep learning job optimization, hardware innovations, and AI-driven optimization enhance GPU efficiency and cost-effectiveness in deep learning applications.